


In today's data-driven world, organizations deal with vast amounts of data that require proper management and analysis. One crucial aspect of this data management is the ETL (Extract, Transform, Load) process.
ETL is a systematic approach to extract data from various sources, transform it into a consistent format, and load it into a target destination. This comprehensive guide will take you through the ETL process, its steps, best practices, tools, and challenges.
What is ETL Process?
ETL is an acronym for Extract, Transform, Load. It's one of the most used data integration process. It's used to collect data from different sources, modify and cleanse it, and then load it into a target system or database. Each component of ETL plays a vital role in ensuring accurate and reliable data integration.
ETL Steps
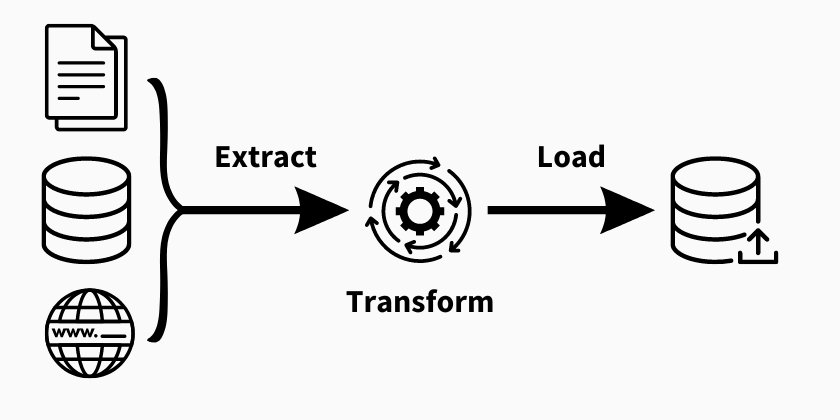
Data Extraction
To initiate the ETL process, the first step involves extracting raw data from relevant sources. This can encompass a diverse range of data origins, such as on-premise databases, CRM systems, data lake, marketing automation platforms, cloud data warehouse, unstructured and structured files, cloud applications, and any other preferred data sources. The extracted data can be structured and unstructured data.
What extraction techniques are available?
- Manual extraction — Manually extracting data involves manually entering or copying data from different sources. This method is suitable for small-scale data extraction but can be time-consuming and error-prone.
- Automated extraction — Automated extraction utilizes software tools or scripts to extract raw data from various sources automatically. It saves time and reduces errors, making it ideal for large-scale data extraction.
What are the different sources from which data can be extracted?
- Relational databases — You can extract data from database management systems such as MySQL, Oracle, SQL Server, PostgreSQL, etc.
- Flat files — You can extract data from flat files such as CSV files, Excel files, delimited text files, etc.
- APIs — Many applications and services expose APIs that allow programmable data extraction. For example, RESTful APIs or SOAP APIs can be used to access data from web services.
- Web sources — You can extract data from websites using web scraping techniques, which involves extracting information from the HTML code of web pages.
- Cloud Data Warehouse — Cloud platforms like Salesforce, Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure offer specific services for data extraction from their environments.
- Real-time data streams — For real-time data, you can extract data from streaming systems such as Apache Kafka, Apache Flink, or by using data stream capture tools.
Our B2B data plays an important role in the ETL process that almost all companies go through. At InfobelPRO, we specifically structure data from over 1,100 different sources, create unique formats for all global business data through data cleansing and transformation processes. We can provide both structured and unstructured B2B data.
If you would like more information, please contact us.
Data Transformation
Once the raw data is extracted, it needs to be transformed into a consistent format that suits the target data warehouse, system or database. This step involves data cleaning, validation, normalization, aggregation, and data enrichment.
To meet the schema requirements of the target database, extracted data undergoes manipulation through a series of functions and rule applications. The extent of transformation required largely depends on the nature of the extracted data and the specific business needs.
What are the different steps in data transformation?
- Data cleansing — Removing missing values, duplicates, incorrect or inconsistent data.
- Normalization and standardization — Harmonizing data formats such as date formats, postal codes, phone numbers, etc.
- Aggregation — Grouping data to obtain aggregated statistics, such as sum, average, maximum, minimum, etc.
- Joining and merging — Combining data from different sources using common keys to create a consolidated view.
- Filtering and selection — Selecting only relevant data for loading, using specific criteria.
- Derived calculations — Performing calculations on existing data to generate new values or additional indicators.
Data Loading
The final step is data loading, where the transformed data is loaded into the target system or database. The loaded data can be stored in a data warehouse, data mart, any data storage, or a specific database for further analysis and reporting.
What are the different ways of loading data?
- Bulk load — Loading data in batches, using massive SQL queries to insert or update records in the target database. Bulk loading is suitable when you have a large volume of data to load into the target database.
- Incremental loading — Loading only the data that has changed since the last run of the process, using mechanisms like timestamps or date/time markers. Incremental loading is useful when you only want to load data that has changed since the last run of the process.
- Real-time insertion — Loading data as it arrives, using streaming mechanisms or stream processing tools. Real-time insertion is employed when immediate data availability is crucial, and you need to load data as it arrives in the system.
- Parallel loading — Parallel loading distributes the data across multiple loading processes or servers simultaneously. Parallel loading is beneficial when you have a large dataset and want to optimize loading speed and performance.
- Scheduled batch loading — Scheduling loading tasks at regular intervals, using task automation tools or task schedulers. This technique is useful when data updates occur at predictable intervals, and you want to automate the loading process.
ETL vs. ELT
As mentioned earlier, ETL stands for Extract, Transform and Load. In contrast, ELT rearranges these steps: Extract, Load, Transform. While both processes focus on data preparation and storage, the manner in which they interact with data warehouses varies significantly.
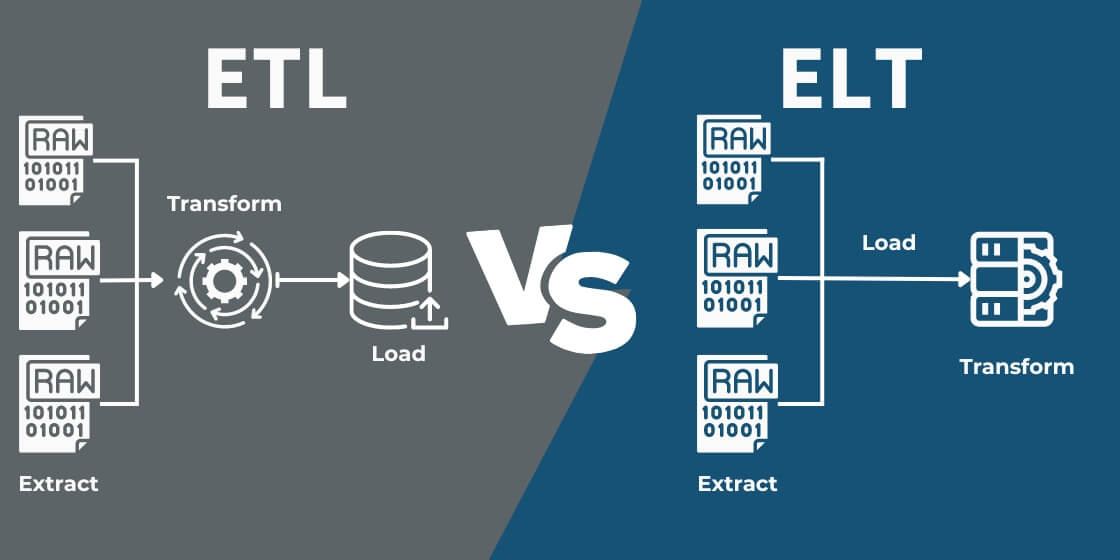
In the traditional ETL approach, data undergoes transformation before it is loaded into the data warehouse. This ensures that only refined and standardized data enters data warehouse, guaranteeing quality right from the outset.
ELT, conversely, capitalizes on the processing prowess of modern data warehousing solutions. Here, raw data is loaded directly into the data warehouse, with transformations occurring afterward.
As data volumes skyrocket and data warehouse technologies advance, the trend is leaning towards ELT. This method harnesses the robust processing capabilities of platforms like Google BigQuery or Amazon Redshift to handle vast transformations efficiently.
The decision between ETL and ELT largely hinges on data nature, the data warehouse's capabilities, and a business's specific requirements. Nonetheless, whether it's through ETL or ELT, the overarching objective is always to provide businesses with accurate, actionable insights from their data, underscoring the pivotal role of the data warehouse in this era of information.
The benefits of ETL
The ETL (Extract, Transform, Load) process offers numerous benefits for organizations dealing with data integration and management. Let's explore some of the key advantages:
- Increased Data Accuracy — Improves data accuracy through cleansing, validation, and enrichment techniques, ensuring high-quality data for analysis and decision-making.
- Improved Data Consistency — Standardizes and transforms data from diverse sources into a consistent format, facilitating seamless integration and accurate comparisons.
- Reduced Data Duplication — By employing data deduplication techniques, the ETL process identifies and eliminates duplicate records, ensuring a single source of truth and avoiding unnecessary storage costs.
- Faster Data Access — Organizes data in a unified format, enabling swift and efficient access for reporting, data analytics, and timely decision-making.
- Improved Data Security — Implements security measures like access controls, encryption, and masking, ensuring data security, privacy compliance, and maintaining data integrity.
ETL Best Practices
The process of extracting, transforming, and loading data, commonly known as ETL, plays a critical role in the success of data integration and analysis.
To ensure efficient and reliable data processing, organizations adopt various best practices that help optimize the ETL process :
- Data analysis and profiling — Before starting the process, it is essential to analyze and profile the source data to understand its structure, quality, and relationships.
- Error handling and data quality checks — Implementing robust error handling mechanisms and performing data quality checks at each stage of the process ensures reliable data integration.
- Data security and compliance — Ensure data security and compliance with privacy regulations by implementing appropriate security measures, access controls, and encryption techniques.
- Documentation and version control — Maintain detailed documentation of the ETL process, including data mappings, transformations, and business rules. Use version control to track changes and ensure reproducibility.
ETL Tools and Technologies
There are several ETL tools available in the market that facilitate the ETL process. Some popular tools include Informatica PowerCenter, Talend, Microsoft SQL Server Integration Services (SSIS), and Apache Nifi. These tools provide features for data extraction, transformation, and loading, along with scheduling, monitoring, and error handling capabilities. It's essential to choose an etl tool that aligns with your organization's specific requirements.
Challenges in the ETL Process
While this process offers numerous benefits in terms of data integration and analysis, it is not without its challenges. Businesses face various obstacles that can impact the efficiency, scalability, and security of the ETL process.
These challenges encompass complexities related to data integration, scalability and performance issues, as well as data governance and privacy concerns :
- Data integration— Integrating data from multiple sources with varying formats and structures can be challenging. It requires careful data mapping and transformation.
- Scalability and performance — Handling large volumes of data and ensuring efficient performance during the process can be demanding. Optimization techniques like parallel processing and data partitioning can address scalability concerns.
- Data governance and privacy — Maintaining data governance, ensuring data privacy, and complying with regulations like GDPR and CCPA are crucial aspects of the ETL process. Implementing appropriate security measures and access controls is necessary.
Future Trends in ETL
The field of Extract, Transform, Load (ETL) is continuously evolving to meet the growing demands of data integration and analysis.
.png?width=1120&height=560&name=Cloud%20Based%20(1).png)
As technology advances, several trends are emerging that shape the future of ETL processes :
- Cloud-based ETL — As more data warehouses move to the cloud, Cloud-based ETL solutions are becoming increasingly popular. They offer a number of advantages over traditional on-premises solutions, such as scalability, flexibility, and cost-effectiveness.
- Real-time ETL — Real-time ETL is becoming increasingly important, as businesses need to be able to access and analyze data in real time to make informed decisions.
- Self-service ETL — Self-service ETL solutions are becoming increasingly popular, as they allow business users to extract, transform, and load data without the need for IT assistance.
- Data virtualization — Data virtualization is a technology that allows businesses to access data from multiple sources without having to physically move the data. This can simplify the ETL process and make it more efficient.
- Machine learning — Machine learning is being used to automate many of the tasks involved in ETL, such as data cleansing and data profiling. This can help to improve the accuracy and efficiency of the ETL process.
FAQs
Is the ETL process only applicable to large organizations?
No, the ETL process is applicable to organizations of all sizes. Any business that deals with data integration from multiple sources can benefit from implementing the ETL process.
How can data quality be ensured during the ETL process?
Data quality can be ensured during the ETL process by implementing data validation rules, performing data profiling and analysis, and conducting data quality checks at each stage of extraction, transformation, and loading.
What are some common challenges faced during data transformation?
Common challenges during data transformation include handling complex data mappings, dealing with data inconsistencies, managing data quality issues, and ensuring efficient performance while processing large volumes of data.
Are there any open-source ETL tools available?
Yes, there are several open-source ETL tools available, such as Apache Nifi, Talend Open Studio, and Pentaho Data Integration. These tools provide robust features for data extraction, transformation, and loading, and can be customized to meet specific requirements.








Comments