


In de huidige datagestuurde wereld hebben organisaties te maken met enorme hoeveelheden gegevens die goed beheerd en geanalyseerd moeten worden. Een cruciaal aspect van dit gegevensbeheer is het ETL-proces (Extract, Transform, Load).
ETL is een systematische aanpak om gegevens te extraheren uit verschillende bronnen, te transformeren naar een consistent formaat en te laden naar een doelbestemming. Deze uitgebreide gids neemt je mee door het ETL proces, de stappen, best practices, tools en uitdagingen.
Wat is het ETL proces?
ETL is een acroniem voor Extract, Transform, Load. Het is een proces dat gebruikt wordt om gegevens uit verschillende bronnen te verzamelen, ze te wijzigen en op te schonen en ze dan in een doelsysteem of database te laden. Elk onderdeel van ETL speelt een vitale rol in het garanderen van nauwkeurige en betrouwbare gegevensintegratie.
ETL processtappen
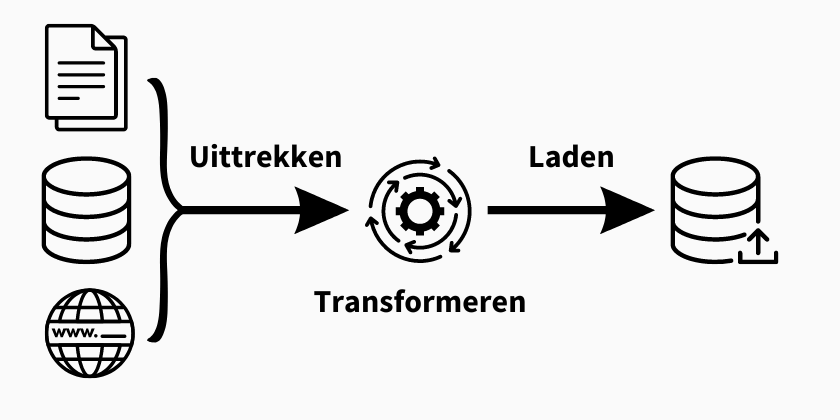
GEGEVENSEXTRACTIE
Om het ETL-proces te starten, bestaat de eerste stap uit het extraheren van gegevens uit relevante bronnen. Dit kan een breed scala aan gegevensbronnen omvatten, zoals lokale databases, CRM-systemen, data lake, marketingautomatiseringsplatforms, cloud data warehouses, ongestructureerde en gestructureerde bestanden, cloud applicaties en andere gewenste gegevensbronnen. De geëxtraheerde gegevens kunnen gestructureerde en ongestructureerde gegevens zijn.
Welke extractietechnieken zijn beschikbaar?
- Handmatige extractie - Het handmatig extraheren van gegevens bestaat uit het handmatig invoeren of kopiëren van gegevens uit verschillende bronnen. Deze methode is geschikt voor kleinschalige gegevensextractie, maar kan tijdrovend en foutgevoelig zijn.
- Geautomatiseerde extractie - Geautomatiseerde extractie maakt gebruik van softwaretools of scripts om ruwe gegevens automatisch uit verschillende bronnen te extraheren. Het bespaart tijd en vermindert fouten, waardoor het ideaal is voor grootschalige gegevensextractie.
Wat zijn de verschillende bronnen waaruit gegevens kunnen worden geëxtraheerd?
- Relationele databases - Je kunt gegevens extraheren uit databasemanagementsystemen zoals MySQL, Oracle, SQL Server, PostgreSQL, enz.
- Platte bestanden - Je kunt gegevens extraheren uit platte bestanden zoals CSV-bestanden, Excel-bestanden, afgebakende tekstbestanden, enz.
- API's - Veel applicaties en diensten stellen API's beschikbaar die programmeerbare gegevensextractie mogelijk maken. RESTful API's of SOAP API's kunnen bijvoorbeeld worden gebruikt om gegevens te extraheren uit webservices.
- Webbronnen - Je kunt gegevens van websites halen met behulp van web scrapingtechnieken, waarbij informatie uit de HTML-code van webpagina's wordt gehaald.
- Cloud Data Warehouses - Cloudplatforms zoals Salesforce, Amazon Web Services (AWS), Google Cloud Platform (GCP) en Microsoft Azure bieden specifieke services voor gegevensextractie uit hun omgevingen.
- Real-time datastromen - Voor real-time gegevens kunt u gegevens extraheren uit streaming systemen zoals Apache Kafka, Apache Flink of door gebruik te maken van tools voor het vastleggen van datastromen.
Onze B2B-gegevens spelen een belangrijke rol in het ETL-proces dat bijna alle bedrijven doorlopen. Bij InfobelPro structureren we specifiek gegevens uit meer dan 1100 verschillende bronnen. We creëren unieke formaten voor alle wereldwijde bedrijfsgegevens. We kunnen zowel gestructureerde als niet-gestructureerde data leveren. Ons team van experts reinigt en transformeert data.
Wilt u meer informatie? Bezoek onze contactpagina om contact met ons op te nemen.
GEGEVENSTRANSFORMATIE
Zodra de gegevens zijn geëxtraheerd, moeten ze worden getransformeerd naar een consistent formaat dat past bij het doel datawarehouse, -systeem of -database. Deze stap omvat het opschonen, valideren, normaliseren, aggregeren en verrijken van gegevens.
Om te voldoen aan de schemavereisten van de doeldatabase, worden de geëxtraheerde gegevens gemanipuleerd via een reeks functies en regelapplicaties. De mate van transformatie die nodig is, hangt grotendeels af van de aard van de geëxtraheerde gegevens en de specifieke bedrijfsbehoeften.
Wat zijn de verschillende stappen in gegevenstransformatie?
- Gegevens opschonen - Ontbrekende waarden, duplicaten, onjuiste of inconsistente gegevens verwijderen.
- Normalisatie en standaardisatie - Harmoniseren van dataformaten zoals datumformaten, postcodes, telefoonnummers, etc.
- Aggregatie - Gegevens groeperen om geaggregeerde statistieken te verkrijgen, zoals som, gemiddelde, maximum, minimum, enz.
- Samenvoegen en samenvoegen - Het combineren van gegevens uit verschillende bronnen met behulp van gemeenschappelijke sleutels om een geconsolideerde weergave te maken.
- Filteren en selecteren - Alleen relevante gegevens selecteren om te laden, met behulp van specifieke criteria.
- Afgeleide berekeningen - berekeningen uitvoeren op bestaande gegevens om nieuwe waarden of aanvullende indicatoren te genereren.
GEGEVENS LADEN
De laatste stap is het laden van gegevens, waarbij de getransformeerde gegevens in het doelsysteem of de database worden geladen. De geladen gegevens kunnen worden opgeslagen in een datawarehouse, data mart of een specifieke database voor verdere analyse en rapportage.
Wat zijn de verschillende manieren om gegevens te laden?
- Bulkbelasting - Gegevens in batches laden met behulp van massieve SQL-query's om records in de doeldatabase in te voegen of bij te werken. Bulkladen is geschikt als je een groot volume aan gegevens in de doeldatabase wilt laden.
- Incrementeel laden - Alleen de gegevens laden die veranderd zijn sinds de laatste run van het ETL proces, met behulp van mechanismen zoals tijdstempels of datum/tijd markers. Incrementeel laden is nuttig als je alleen gegevens wilt laden die zijn veranderd sinds de laatste run van het proces.
- Real-time invoegen - Gegevens laden wanneer ze binnenkomen, met behulp van streaming mechanismen of tools voor streamverwerking. Real-time invoegen wordt gebruikt als onmiddellijke beschikbaarheid van gegevens cruciaal is en je gegevens moet laden zodra ze in het systeem aankomen.
- Parallel laden - Parallel laden verdeelt de gegevens over meerdere laadprocessen of servers tegelijk. Parallel laden is voordelig als je een grote dataset hebt en de laadsnelheid en -prestaties wilt optimaliseren.
- Geplande batchbelading - Beladingstaken op regelmatige tijdstippen plannen met behulp van tools voor taakautomatisering of taakplanners. Deze techniek is nuttig als gegevensupdates op voorspelbare intervallen voorkomen en je het laadproces wilt automatiseren.
De voordelen van ETL
Het ETL-proces (Extract, Transform, Load) biedt tal van voordelen voor organisaties die zich bezighouden met gegevensintegratie en -beheer. Laten we eens een paar van de belangrijkste voordelen van het implementeren van een ETL proces bekijken:
- Verbeterde nauwkeurigheid van gegevens - Verbetert de nauwkeurigheid van gegevens door middel van opschoning, validatie en verrijkingstechnieken, waardoor gegevens van hoge kwaliteit worden gegarandeerd voor analyse en besluitvorming.
- Verbeterde consistentie van gegevens - Standaardiseert en transformeert gegevens uit verschillende bronnen naar een consistent formaat, waardoor naadloze integratie en nauwkeurige vergelijkingen mogelijk worden.
- Minder dubbele gegevens - Door gebruik te maken van technieken voor het ontdubbelen van gegevens identificeert en elimineert het ETL-proces dubbele records, waardoor één enkele bron van waarheid ontstaat en onnodige opslagkosten worden vermeden.
- Snellere toegang tot gegevens - Organiseert gegevens in een uniform formaat, waardoor snelle en efficiënte toegang mogelijk is voor rapportage, gegevensanalyse en tijdige besluitvorming.
- Verbeterde gegevensbeveiliging - Implementeert beveiligingsmaatregelen zoals toegangscontroles, versleuteling en maskering, zodat gegevens veilig zijn, de privacy wordt gerespecteerd en de gegevensintegriteit behouden blijft.
ETL Best Practices
Het proces van het extraheren, transformeren en laden van gegevens, beter bekend als ETL, speelt een cruciale rol in het succes van data-integratie en -analyse.
Om een efficiënte en betrouwbare gegevensverwerking te garanderen, passen organisaties verschillende best practices toe die het ETL-proces helpen optimaliseren:
- Gegevensanalyse en profilering - Voordat het ETL proces begint, is het essentieel om de brongegevens te analyseren en te profileren om de structuur, kwaliteit en relaties te begrijpen.
- Foutafhandeling en datakwaliteitscontroles - Het implementeren van robuuste foutafhandelingsmechanismen en het uitvoeren van datakwaliteitscontroles in elke fase van het ETL-proces zorgt voor een betrouwbare data-integratie.
- Gegevensbeveiliging en compliance - Zorg voor gegevensbeveiliging en compliance met privacyregels door de juiste beveiligingsmaatregelen, toegangscontroles en versleutelingstechnieken te implementeren.
- Documentatie en versiebeheer - Houd gedetailleerde documentatie bij van het ETL-proces, inclusief datatoewijzingen, transformaties en bedrijfsregels. Gebruik versiebeheer om wijzigingen bij te houden en reproduceerbaarheid te garanderen.
ETL hulpmiddelen en technologieën
Er zijn verschillende ETL tools op de markt die het ETL proces vergemakkelijken. Enkele populaire tools zijn Informatica PowerCenter, Talend, Microsoft SQL Server Integration Services (SSIS) en Apache Nifi. Deze tools bieden functies voor het extraheren, transformeren en laden van gegevens, samen met mogelijkheden voor planning, bewaking en foutafhandeling. Het is essentieel om een tool te kiezen die aansluit bij de specifieke vereisten van je organisatie.
Uitdagingen in het ETL proces
Hoewel het ETL proces talrijke voordelen biedt op het gebied van gegevensintegratie en -analyse, is het niet zonder uitdagingen. Bedrijven worden geconfronteerd met verschillende obstakels die de efficiëntie, schaalbaarheid en veiligheid van het ETL proces kunnen beïnvloeden.
Deze uitdagingen omvatten complexiteiten die te maken hebben met data-integratie, schaalbaarheid en prestatieproblemen, maar ook zorgen over data governance en privacy:
- Complexiteit data-integratie - Het integreren van data uit meerdere bronnen met verschillende formaten, structuren en datakwaliteitsniveaus kan een uitdaging zijn. Dit vereist het zorgvuldig in kaart brengen en transformeren van gegevens.
- Schaalbaarheid en prestatieproblemen - Het verwerken van grote hoeveelheden gegevens en het garanderen van efficiënte prestaties tijdens het ETL proces kan veeleisend zijn. Optimalisatietechnieken zoals parallelle verwerking en datapartitionering kunnen de schaalbaarheidsproblemen oplossen.
- Gegevensbeheer en privacy - Het onderhouden van gegevensbeheer, het waarborgen van gegevensprivacy en het voldoen aan voorschriften zoals GDPR en CCPA zijn cruciale aspecten van het ETL-proces. Het implementeren van de juiste beveiligingsmaatregelen en toegangscontroles is noodzakelijk.
Toekomstige trends in ETL
Het domein van Extract, Transform, Load (ETL) evolueert voortdurend om tegemoet te komen aan de groeiende vraag naar data-integratie en -analyse.
Naarmate de technologie voortschrijdt, ontstaan er verschillende trends die de toekomst van ETL-processen vormgeven:
- Cloud-gebaseerde ETL - Cloud-gebaseerde ETL oplossingen worden steeds populairder omdat ze een aantal voordelen bieden ten opzichte van traditionele oplossingen op locatie, zoals schaalbaarheid, flexibiliteit en kosteneffectiviteit.
- Realtime ETL - Realtime ETL wordt steeds belangrijker omdat bedrijven gegevens in realtime moeten kunnen opvragen en analyseren om weloverwogen beslissingen te kunnen nemen.
- Self-service ETL - Self-service ETL oplossingen worden steeds populairder omdat ze zakelijke gebruikers in staat stellen gegevens te extraheren, te transformeren en te laden zonder de hulp van IT nodig te hebben.
- Datavirtualisatie - Datavirtualisatie is een technologie die bedrijven toegang geeft tot gegevens uit meerdere bronnen zonder dat ze de gegevens fysiek hoeven te verplaatsen. Dit kan het ETL-proces vereenvoudigen en efficiënter maken.
- Machine learning - Machine learning wordt gebruikt om veel van de taken bij ETL te automatiseren, zoals het opschonen van gegevens en het profileren van gegevens. Dit kan helpen om de nauwkeurigheid en efficiëntie van het ETL proces te verbeteren.
ETL proces: veelgestelde vragen
WAT IS HET VERSCHIL TUSSEN ETL EN ELT?
Bij ETL (Extract, Transform, Load) worden gegevens geëxtraheerd, getransformeerd en vervolgens in een doelsysteem geladen. ELT (Extract, Load, Transform) volgt een vergelijkbaar proces, maar laadt de gegevens eerst in een doelsysteem en voert dan transformaties uit binnen het doelsysteem.
IS HET ETL-PROCES ALLEEN VAN TOEPASSING OP GROTE ORGANISATIES?
Nee, het ETL-proces is van toepassing op organisaties van alle groottes. Elk bedrijf dat te maken heeft met gegevensintegratie vanuit meerdere bronnen kan profiteren van de implementatie van het ETL proces.
HOE KAN DE DATAKWALITEIT WORDEN GEWAARBORGD TIJDENS HET ETL PROCES?
Datakwaliteit kan worden gewaarborgd tijdens het ETL proces door het implementeren van datavalidatieregels, het uitvoeren van dataprofilering en -analyse en het uitvoeren van datakwaliteitscontroles in elke fase van extractie, transformatie en laden.
WAT ZIJN ENKELE VEELVOORKOMENDE UITDAGINGEN TIJDENS DATATRANSFORMATIE?
Veel voorkomende uitdagingen tijdens datatransformatie zijn het omgaan met complexe datatransformaties, het omgaan met inconsistenties in data, het beheren van datakwaliteitsproblemen en het waarborgen van efficiënte prestaties tijdens het verwerken van grote hoeveelheden data.
ZIJN ER OPEN-SOURCE ETL-TOOLS BESCHIKBAAR?
Ja, er zijn verschillende open-source ETL tools beschikbaar, zoals Apache Nifi, Talend Open Studio en Pentaho Data Integration. Deze tools bieden robuuste functies voor het extraheren, transformeren en laden van gegevens en kunnen worden aangepast om aan specifieke eisen te voldoen.








Reacties